DeepReinforce 是一家人工智能研究实验室,之前以 CUDA-L1 和 IterX 代码代理优化循环而闻名,上周晚些时候发布了 Ornith-1.0 — Hugging Face 上提供的一系列开源编码模型,根据参数数量有四种尺寸:9 10 亿、310 亿、350 亿的专家混合体,以及 3970 亿的专家混合旗舰,所有这些都在 MIT 许可下,没有区域限制。
参数基本上是模型在训练中可以处理的刻度盘和配置的数量。参数越多,模型的能力就越强。 90 亿参数的模型被认为很小,足以在优质智能手机上运行,但无法可靠地执行任何繁重的推理任务。 3970 亿个模型的能力要强得多,但需要一些繁重的计算,而这种计算在消费类硬件上是不可用的。
实验室将其描述为“一个自我改进的开源模型系列,专门用于代理编码任务。” “代理”这个词发挥了很大的作用。
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding.
Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on… pic.twitter.com/7g1rmacLps
— Ornith (@ornith_) June 25, 2026
人们与之互动的大多数人工智能都是对话式的:你输入,它做出响应,交流结束。 代理人工智能则不同——它获取任务并采取行动来完成它,而无需人类指导每一步。在编码环境中,这意味着人工智能可以读取文件、运行测试、识别失败的内容、修复代码并再次循环直到完成。
因此,Agentic AI 意味着大多数时间都不需要有人坐在键盘上。这就是重点。这也是 2026 年最具商业相关性进展的方向——可以通过 20 步开发工作流程无监督运行的模型比根据请求编写干净函数的模型更有价值。
但是,大多数大型语言模型的设计仍然考虑了人类反馈。
Ornith 的大脑如何工作
大多数人工智能编码代理都与人工设计的工具配对,这是代理如何构建其工作的一组固定规则:何时调用工具、如何处理错误、如何分解多步骤问题。 Ornith 相反“将脚手架视为与策略共同进化的可学习对象。”
翻译:它没有继承别人的剧本,而是开发自己的剧本。
在强化学习期间,每个训练步骤都分两个阶段进行。该模型首先读取任务并提出处理该任务的改进策略。然后它使用该策略生成解决方案。
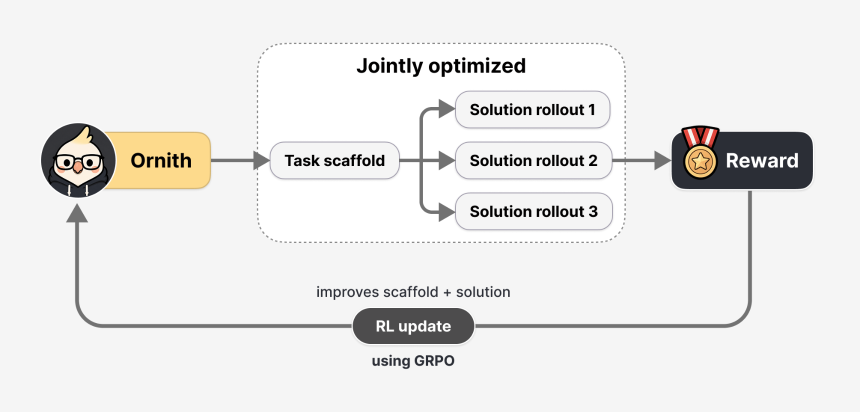
结果的奖励会回流到两个阶段,因此模型经过优化,可以编写更好的策略,而不仅仅是更好的代码。这样做成千上万次,特定于任务的方法就会出现,而无需人工设计。
DeepReinforce 也严肃对待奖励黑客行为。如果模型可以编写自己的训练支架,那么理论上它可以编写一个与验证者进行游戏的支架——触摸文件,使其看起来像是完成了一项任务,但实际上并没有做任何工作。三层防御阻止了这一点:环境和测试套件是不可变的,并且在模型的范围之外,确定性监视器会标记任何访问受限路径或更改验证脚本的尝试,并且冻结的判断模型位于自动验证器之上作为否决权。
数字
旗舰级 3970 亿参数模型在 SWE-bench Verified 上得分为 82.4,这是一项测试,其中人工智能从开源 GitHub 存储库中获得一个真正的错误,并且必须在不查看测试套件的情况下修复它,并根据成功解决的问题的百分比进行评分。
在同一测试中,这超过了 Claude Opus 4.7 的 80.8 和 DeepSeek-V4-Pro 的 80.6。在 Terminal Bench 2.1 上,89 个任务在容器化终端环境中运行,从调试异步代码到解决安全漏洞,按完成率评分,它的得分为 77.5,而 Claude Opus 4.7 的得分为 70.3。 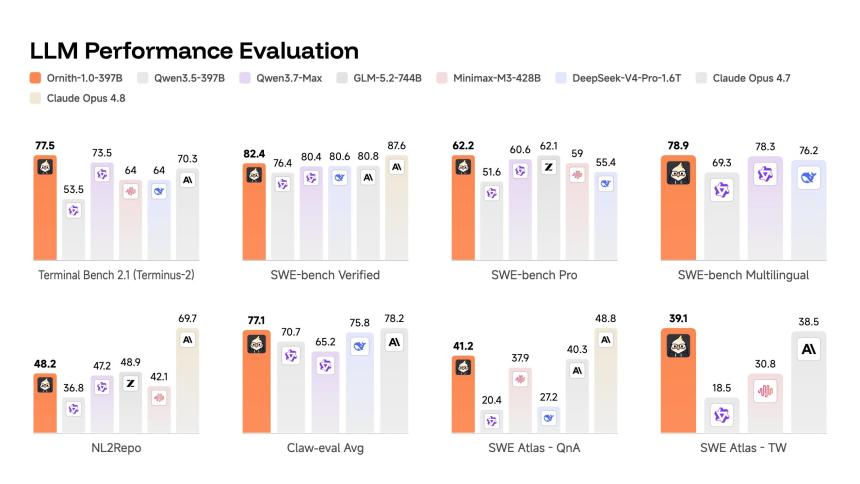
考虑到 SWE-bench 污染问题已被公开提出——OpenAI 今年早些时候表示,模型通过记忆训练期间看到的基准解决方案而夸大了分数——Ornith 还报告了 SWE-bench Pro 上的数据,这是一个使用更多样化、更少泄漏的代码库的更难版本,得分相同。 3970 亿的模型落在 62.2 处。显着降低,但仍然具有竞争力,并且仍然优于 Deepseek V4 Pro。
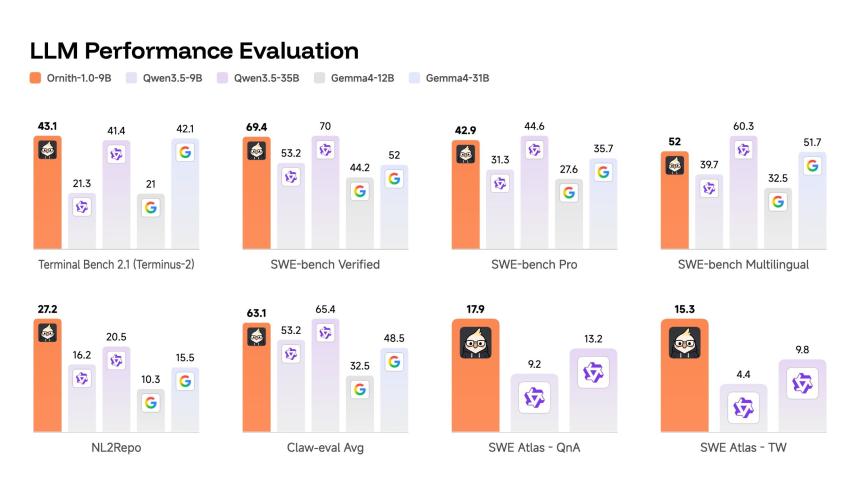
90 亿个参数模型可能是更有趣的数据点。它在 SWE-bench Verified 上的得分为 69.4,高于 Gemma 4-31B 的 52,并且与 Qwen 3.5-35B 的 70 相当,尽管尺寸小了 3-4 倍。
它适合谁,不适合谁
Ornith-1.0 显然不是通用人工智能。该模型自己的文档称,它在代理编码之外的任务上可能表现不佳。如果您希望 AI 总结文档、帮助您撰写博士论文或起草电子邮件,Ornith-1.0 是错误的选择。
它针对狭窄的问题集进行了优化:开发人员通过管道,人工智能代理获取任务描述,在代码存储库或终端会话中进行操作,并在无需干预的情况下完成多步骤工作。这是一个为已经在运行代理基础设施的人构建的工具,而不是为试图决定人工智能是否值得使用的人构建的。
“击败克劳德”标题是真实的,但需要上下文。正如 Decrypt 报道的,每个实验室现在都在追求代理编码评估的性能,因为这就是有用的性能差异所在。
Ornith-1.0-397B 在两个不同的编码基准上确实超过了 Claude Opus 4.7,但 Anthropic 目前的旗舰产品 Claude Opus 4.8 得分更高。进行的比较是在开源类别内、在可比较的参数数量下、在特定于编码的代理任务上进行的。
对于构建自托管编码管道、代理基础设施或类似的以编码为中心的工作的开发人员来说,在边缘硬件上运行的中小型模型可能确实有用,但普通人可能在其他地方会更好。